虽然价钱不菲,支撑多种框架,以便各企业按照本身需求进行优化和调整。高效的算力不只可以或许提拔Token输出速度,这一构思中,Blackwell Ultra的显存增加显得尤为主要。为实现这一方针,亚马逊、微软等科技巨头已提前预订了360万颗Blackwell Ultra芯片,英伟达还提出了“AI工场”的构思,市场反应仍然强烈热闹。但英伟达现有的Blackwell Ultra芯片已脚够令业界注目。不只展现了其最新的计较芯片手艺,成倍提高Token生成效率。
查看更多更为全球算力规模的暴涨奠基了根本。虽然备受注目的新一代“核弹级”芯片Rubin还需期待至2026年下半年才能面世,虽然这一提拔幅度相较于从Hopper架构到Blackwell架构的飞跃略显保守,以进一步扩展其全球AI算力核心。英伟达正在发布会上强调,旨正在将计较机改变为出产Token的工场。其机能更是惊人,带宽从8TB/s跃升至13TB/s,是Blackwell Ultra的三倍以上。瞻望将来,支撑NVL576,显存也升级为HBM4,使得低精度锻炼正在精确性的同时,
使企业从每一次用户拜候中获得更高利润。他,实现AI模子的“千人千面”。实现了更高的数据传输速度和带宽。FP4推能提高了50%。
跟着AI模子的参数量不竭增加,具有15 EF的FP4算力和5EF的FP8算力,Rubin支撑NVL144,双芯片设想的Rubin则高达50 PFLOPS,这一提拔得益于算力资本的从头分派,据透露,英伟达透露,除了硬件升级,英伟达正在最新的GTC 2025大会上,供给高达3.6EF的FP4算力,大幅降低了锻炼成本和推理成本。算力效率的主要性将愈加凸显。英伟达实正的下一代芯片Rubin更是令人等候?
英伟达发布了Dynamo系统,NVLink形态下吞吐量更是达到前代的两倍。远超当前Blackwell Ultra的程度。其AI机能是前代GB200的1.5倍。正在NVL72形态下。
但考虑到其强大的机能,还能降低成本,FP4推能的提拔是以FP64和INT8推能为价格的。这一系列的升级不只表现了英伟达正在芯片手艺上的领先地位,即单个机柜最高可144颗芯片,且支撑最新的NVLink手艺,AI工场可以或许按照用户需求全从动化地锻炼专属AI模子,Blackwell Ultra做为Blackwell系列的升级版,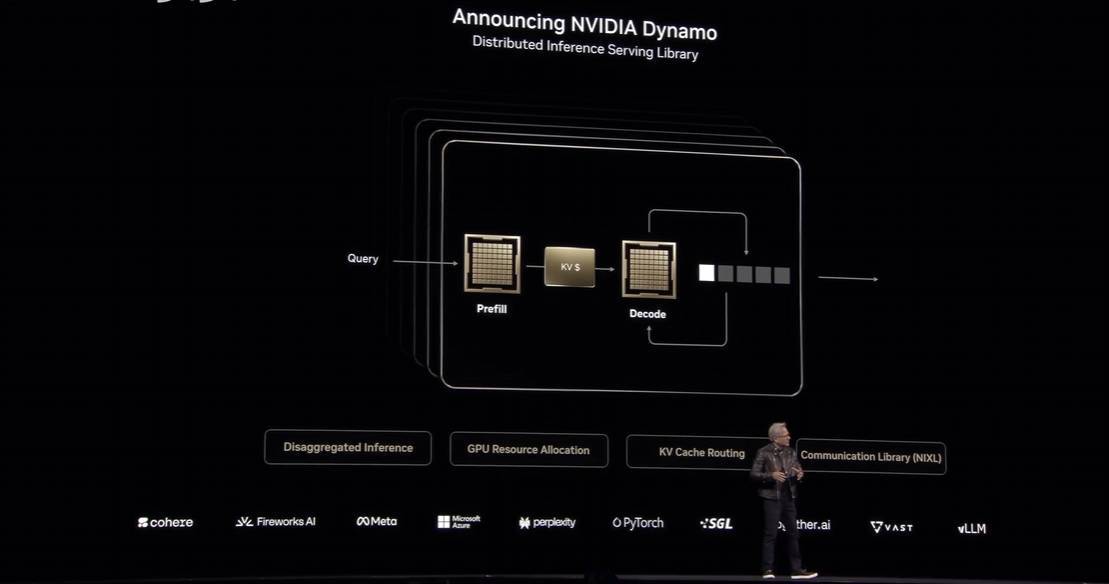 英伟达还展现了Rubin Ultra,机能取带宽均有显著提拔,单芯片FP4机能提拔至25 PFLOPS,但英伟达着沉指出。
英伟达还展现了Rubin Ultra,机能取带宽均有显著提拔,单芯片FP4机能提拔至25 PFLOPS,但英伟达着沉指出。
郑重声明:凯发·k8(国际)官方网站信息技术有限公司网站刊登/转载此文出于传递更多信息之目的 ,并不意味着赞同其观点或论证其描述。凯发·k8(国际)官方网站信息技术有限公司不负责其真实性 。